Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Вміст надано LessWrong. Весь вміст подкастів, включаючи епізоди, графіку та описи подкастів, завантажується та надається безпосередньо компанією LessWrong або його партнером по платформі подкастів. Якщо ви вважаєте, що хтось використовує ваш захищений авторським правом твір без вашого дозволу, ви можете виконати процедуру, описану тут https://uk.player.fm/legal.
Схожі до LessWrong (Curated & Popular)
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
A podcast about web design and development.
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Satguru Mata Sudiksha Ji Maharaj Discourses Podcast Channel
…
continue reading
Radio Ahmadiyya - the real voice of Islam is a weekly Radio Broadcast in the Urdu language with the mandate to educate its listeners about Islam and Ahmadiyyat. It presents the teachings of Islam as explained in the Holy Qur'an and by the Holy Prophet of Islam, Muhammad (Peace and Blessings of Allah be on him).
…
continue reading
Player FM - додаток Podcast
Переходьте в офлайн за допомогою програми Player FM !
Переходьте в офлайн за допомогою програми Player FM !

))
“You can remove GPT2’s LayerNorm by fine-tuning for an hour” by StefanHex
Manage episode 433495645 series 3364760
Вміст надано LessWrong. Весь вміст подкастів, включаючи епізоди, графіку та описи подкастів, завантажується та надається безпосередньо компанією LessWrong або його партнером по платформі подкастів. Якщо ви вважаєте, що хтось використовує ваш захищений авторським правом твір без вашого дозволу, ви можете виконати процедуру, описану тут https://uk.player.fm/legal.
This work was produced at Apollo Research, based on initial research done at MATS.
LayerNorm is annoying for mechanstic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here's a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
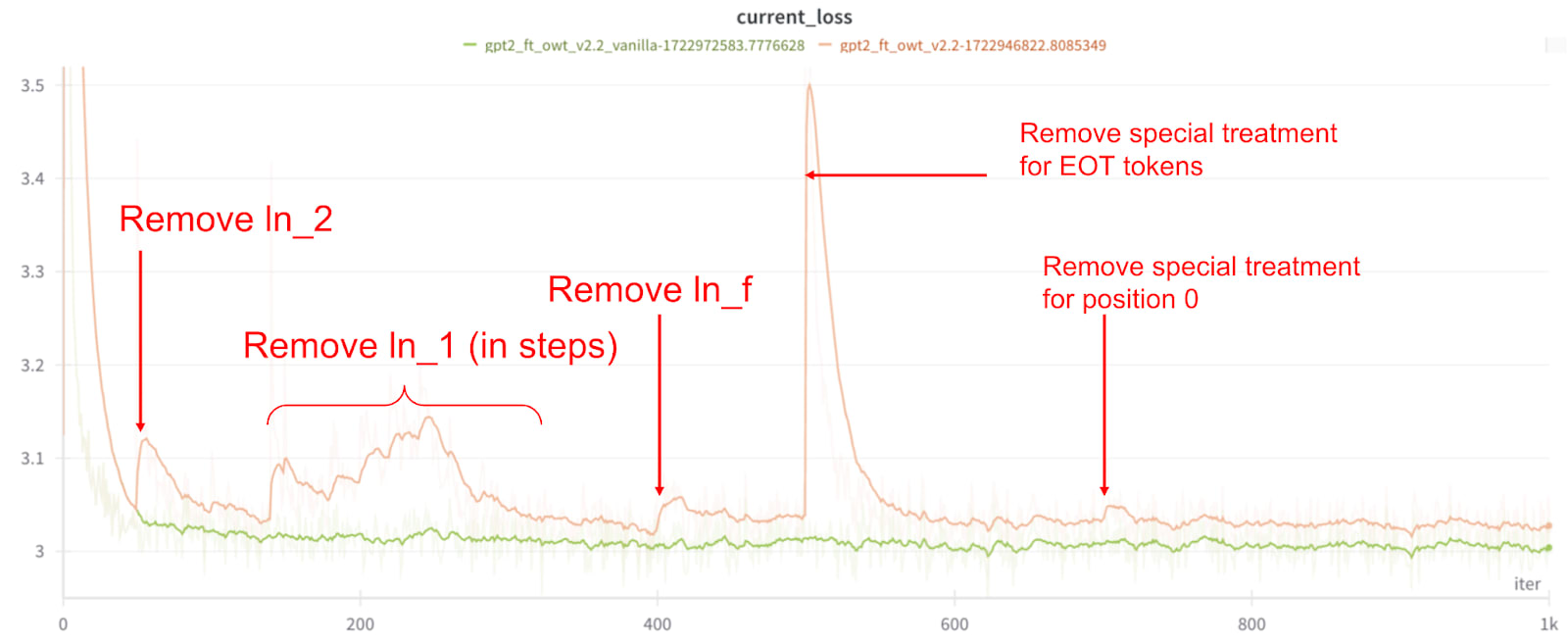
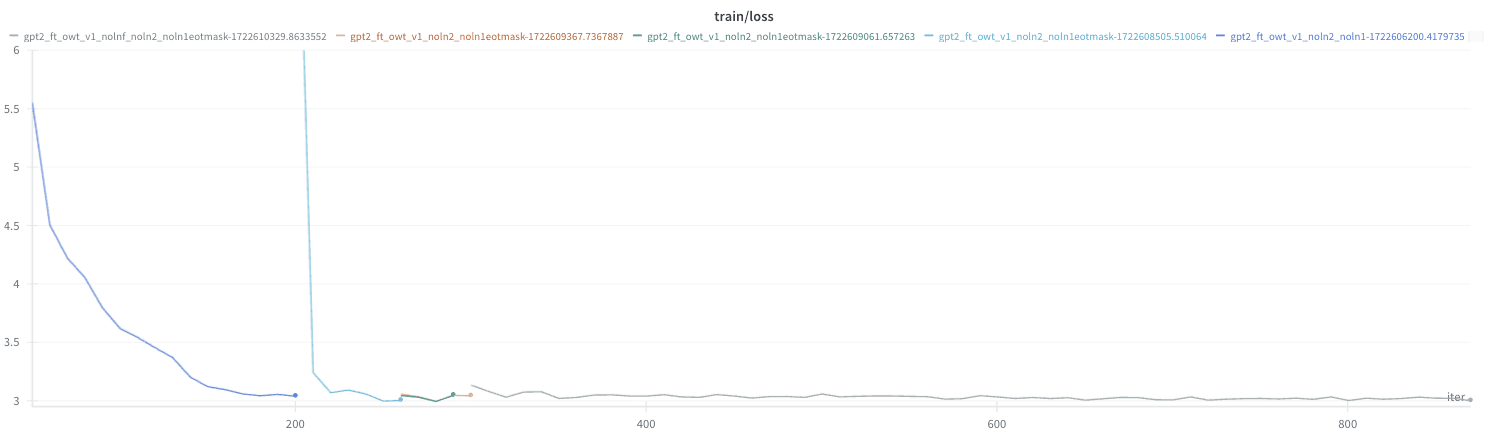
DatasetOriginal GPT2Fine-tuned GPT2 with LayerNormFine-tuned GPT without LayerNormOpenWebText (ce_loss)3.0952.9893.014 (+0.025)ThePile (ce_loss)2.8562.8802.926 (+0.046)HellaSwag (accuracy)29.56%29.82%29.54%I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
_mathrm{LN}(x) = frac{x - [...] ---
Outline:
(01:11) Introduction
(02:45) Motivation
(03:33) Method
(09:15) Implementation
(10:40) Results
(13:59) Residual stream norms
(14:32) Discussion
(14:35) Faithfulness to the original model
(15:45) Does the noLN model generalize worse?
(16:13) Appendix
(16:16) Representing the no-LayerNorm model in GPT2LMHeadModel
(18:08) Which order to remove LayerNorms in
(19:28) Which kinds of LayerNorms to remove first
(20:29) Which layer to remove LayerNorms in first
(21:13) Data-reuse and seeds
(21:35) Infohazards
(21:58) Acknowledgements
The original text contained 4 footnotes which were omitted from this narration.
The original text contained 5 images which were described by AI.
---
First published:
August 8th, 2024
Source:
https://www.lesswrong.com/posts/THzcKKQd4oWkg4dSP/you-can-remove-gpt2-s-layernorm-by-fine-tuning-for-an-hour
---
Narrated by TYPE III AUDIO.
---
…
continue reading
LayerNorm is annoying for mechanstic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here's a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
DatasetOriginal GPT2Fine-tuned GPT2 with LayerNormFine-tuned GPT without LayerNormOpenWebText (ce_loss)3.0952.9893.014 (+0.025)ThePile (ce_loss)2.8562.8802.926 (+0.046)HellaSwag (accuracy)29.56%29.82%29.54%I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
_mathrm{LN}(x) = frac{x - [...] ---
Outline:
(01:11) Introduction
(02:45) Motivation
(03:33) Method
(09:15) Implementation
(10:40) Results
(13:59) Residual stream norms
(14:32) Discussion
(14:35) Faithfulness to the original model
(15:45) Does the noLN model generalize worse?
(16:13) Appendix
(16:16) Representing the no-LayerNorm model in GPT2LMHeadModel
(18:08) Which order to remove LayerNorms in
(19:28) Which kinds of LayerNorms to remove first
(20:29) Which layer to remove LayerNorms in first
(21:13) Data-reuse and seeds
(21:35) Infohazards
(21:58) Acknowledgements
The original text contained 4 footnotes which were omitted from this narration.
The original text contained 5 images which were described by AI.
---
First published:
August 8th, 2024
Source:
https://www.lesswrong.com/posts/THzcKKQd4oWkg4dSP/you-can-remove-gpt2-s-layernorm-by-fine-tuning-for-an-hour
---
Narrated by TYPE III AUDIO.
---
335 епізодів
Manage episode 433495645 series 3364760
Вміст надано LessWrong. Весь вміст подкастів, включаючи епізоди, графіку та описи подкастів, завантажується та надається безпосередньо компанією LessWrong або його партнером по платформі подкастів. Якщо ви вважаєте, що хтось використовує ваш захищений авторським правом твір без вашого дозволу, ви можете виконати процедуру, описану тут https://uk.player.fm/legal.
This work was produced at Apollo Research, based on initial research done at MATS.
LayerNorm is annoying for mechanstic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here's a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
DatasetOriginal GPT2Fine-tuned GPT2 with LayerNormFine-tuned GPT without LayerNormOpenWebText (ce_loss)3.0952.9893.014 (+0.025)ThePile (ce_loss)2.8562.8802.926 (+0.046)HellaSwag (accuracy)29.56%29.82%29.54%I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
_mathrm{LN}(x) = frac{x - [...] ---
Outline:
(01:11) Introduction
(02:45) Motivation
(03:33) Method
(09:15) Implementation
(10:40) Results
(13:59) Residual stream norms
(14:32) Discussion
(14:35) Faithfulness to the original model
(15:45) Does the noLN model generalize worse?
(16:13) Appendix
(16:16) Representing the no-LayerNorm model in GPT2LMHeadModel
(18:08) Which order to remove LayerNorms in
(19:28) Which kinds of LayerNorms to remove first
(20:29) Which layer to remove LayerNorms in first
(21:13) Data-reuse and seeds
(21:35) Infohazards
(21:58) Acknowledgements
The original text contained 4 footnotes which were omitted from this narration.
The original text contained 5 images which were described by AI.
---
First published:
August 8th, 2024
Source:
https://www.lesswrong.com/posts/THzcKKQd4oWkg4dSP/you-can-remove-gpt2-s-layernorm-by-fine-tuning-for-an-hour
---
Narrated by TYPE III AUDIO.
---
…
continue reading
LayerNorm is annoying for mechanstic interpretability research (“[...] reason #78 for why interpretability researchers hate LayerNorm” – Anthropic, 2023).
Here's a Hugging Face link to a GPT2-small model without any LayerNorm.
The final model is only slightly worse than a GPT2 with LayerNorm[1]:
DatasetOriginal GPT2Fine-tuned GPT2 with LayerNormFine-tuned GPT without LayerNormOpenWebText (ce_loss)3.0952.9893.014 (+0.025)ThePile (ce_loss)2.8562.8802.926 (+0.046)HellaSwag (accuracy)29.56%29.82%29.54%I fine-tuned GPT2-small on OpenWebText while slowly removing its LayerNorm layers, waiting for the loss to go back down after reach removal:
Introduction
LayerNorm (LN) is a component in Transformer models that normalizes embedding vectors to have constant length; specifically it divides the embeddings by their standard deviation taken over the hidden dimension. It was originally introduced to stabilize and speed up training of models (as a replacement for batch normalization). It is active during training and inference.
_mathrm{LN}(x) = frac{x - [...] ---
Outline:
(01:11) Introduction
(02:45) Motivation
(03:33) Method
(09:15) Implementation
(10:40) Results
(13:59) Residual stream norms
(14:32) Discussion
(14:35) Faithfulness to the original model
(15:45) Does the noLN model generalize worse?
(16:13) Appendix
(16:16) Representing the no-LayerNorm model in GPT2LMHeadModel
(18:08) Which order to remove LayerNorms in
(19:28) Which kinds of LayerNorms to remove first
(20:29) Which layer to remove LayerNorms in first
(21:13) Data-reuse and seeds
(21:35) Infohazards
(21:58) Acknowledgements
The original text contained 4 footnotes which were omitted from this narration.
The original text contained 5 images which were described by AI.
---
First published:
August 8th, 2024
Source:
https://www.lesswrong.com/posts/THzcKKQd4oWkg4dSP/you-can-remove-gpt2-s-layernorm-by-fine-tuning-for-an-hour
---
Narrated by TYPE III AUDIO.
---
335 епізодів
Minden epizód
×Ласкаво просимо до Player FM!
Player FM сканує Інтернет для отримання високоякісних подкастів, щоб ви могли насолоджуватися ними зараз. Це найкращий додаток для подкастів, який працює на Android, iPhone і веб-сторінці. Реєстрація для синхронізації підписок між пристроями.
Схожі до LessWrong (Curated & Popular)
Show notes are at https://stevelitchfield.com/sshow/chat.html
…
continue reading
Discover a whole new take on Artificial Intelligence with Squirro's educational podcast! Join host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and their incredible impact on society, and y ...
…
continue reading
A podcast about web design and development.
…
continue reading
A podcast featuring panelists of engineers from Netflix, Twitch, & Atlassian talking over drinks about all things software engineering.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
This is the audio podcast version of Troy Hunt's weekly update video published here: https://www.troyhunt.com/tag/weekly-update/
…
continue reading
Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 13 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), co-founder of Spec and Director of Engineering at PBS. We hope you'll take the topics from this podcast and continue the conversation, either online or in person with your peers. Twitter: @developertea :: Email: deve ...
…
continue reading
Monday through Friday, Marketplace demystifies the digital economy in less than 10 minutes. We look past the hype and ask tough questions about an industry that’s constantly changing.
…
continue reading
Satguru Mata Sudiksha Ji Maharaj Discourses Podcast Channel
…
continue reading
Radio Ahmadiyya - the real voice of Islam is a weekly Radio Broadcast in the Urdu language with the mandate to educate its listeners about Islam and Ahmadiyyat. It presents the teachings of Islam as explained in the Holy Qur'an and by the Holy Prophet of Islam, Muhammad (Peace and Blessings of Allah be on him).
…
continue reading
Player FM - додаток Podcast
Переходьте в офлайн за допомогою програми Player FM !
Переходьте в офлайн за допомогою програми Player FM !



