The award-winning WIRED UK Podcast with James Temperton and the rest of the team. Listen every week for the an informed and entertaining rundown of latest technology, science, business and culture news. New episodes every Friday.
…
continue reading
Вміст надано LessWrong. Весь вміст подкастів, включаючи епізоди, графіку та описи подкастів, завантажується та надається безпосередньо компанією LessWrong або його партнером по платформі подкастів. Якщо ви вважаєте, що хтось використовує ваш захищений авторським правом твір без вашого дозволу, ви можете виконати процедуру, описану тут https://uk.player.fm/legal.
Схожі до LessWrong (Curated & Popular)
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Player FM - додаток Podcast
Переходьте в офлайн за допомогою програми Player FM !
Переходьте в офлайн за допомогою програми Player FM !

))
“How Well Does RL Scale?” by Toby_Ord
Manage episode 516788581 series 3364760
Вміст надано LessWrong. Весь вміст подкастів, включаючи епізоди, графіку та описи подкастів, завантажується та надається безпосередньо компанією LessWrong або його партнером по платформі подкастів. Якщо ви вважаєте, що хтось використовує ваш захищений авторським правом твір без вашого дозволу, ви можете виконати процедуру, описану тут https://uk.player.fm/legal.
This is the latest in a series of essays on AI Scaling.
You can find the others on my site.
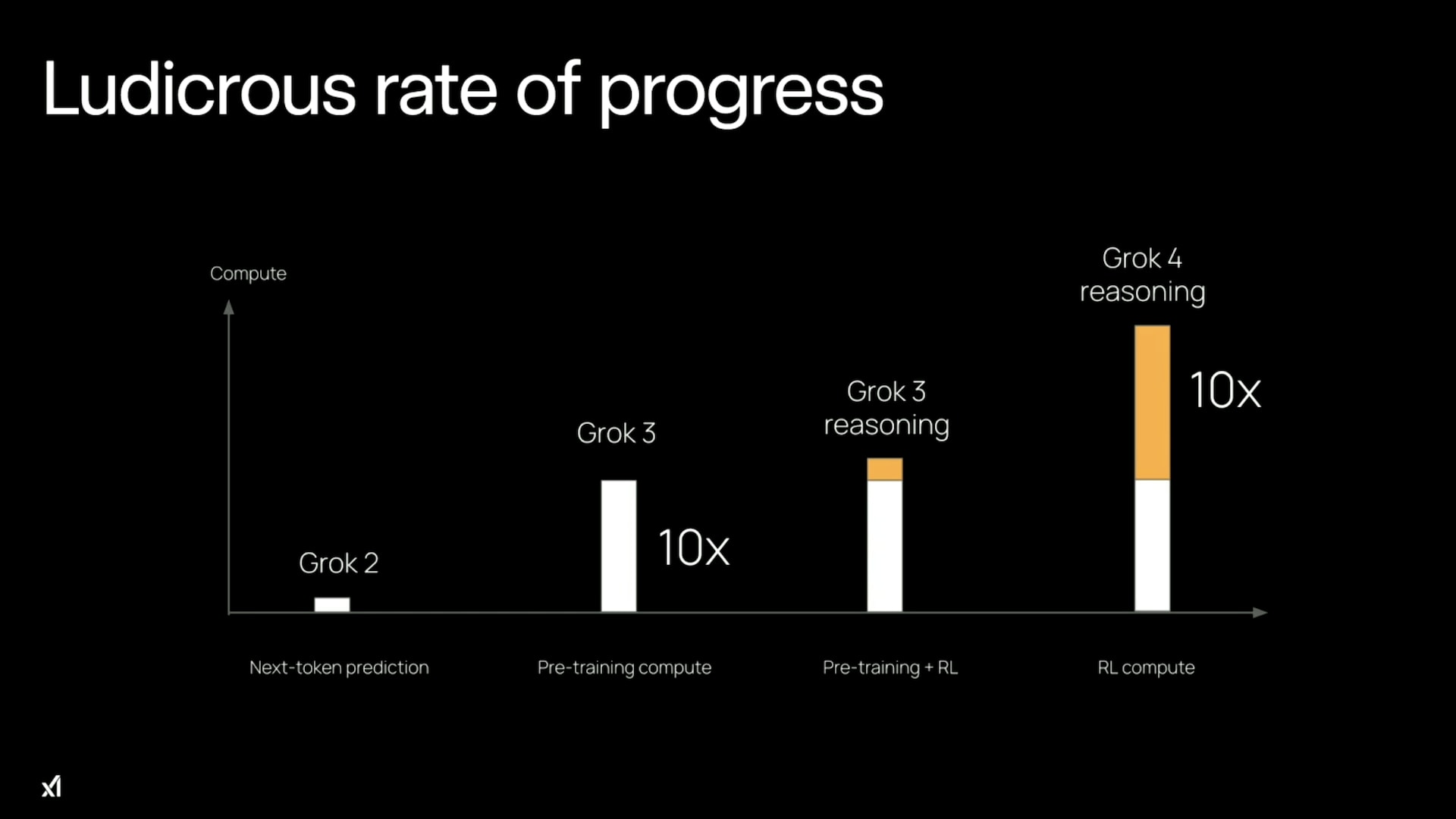
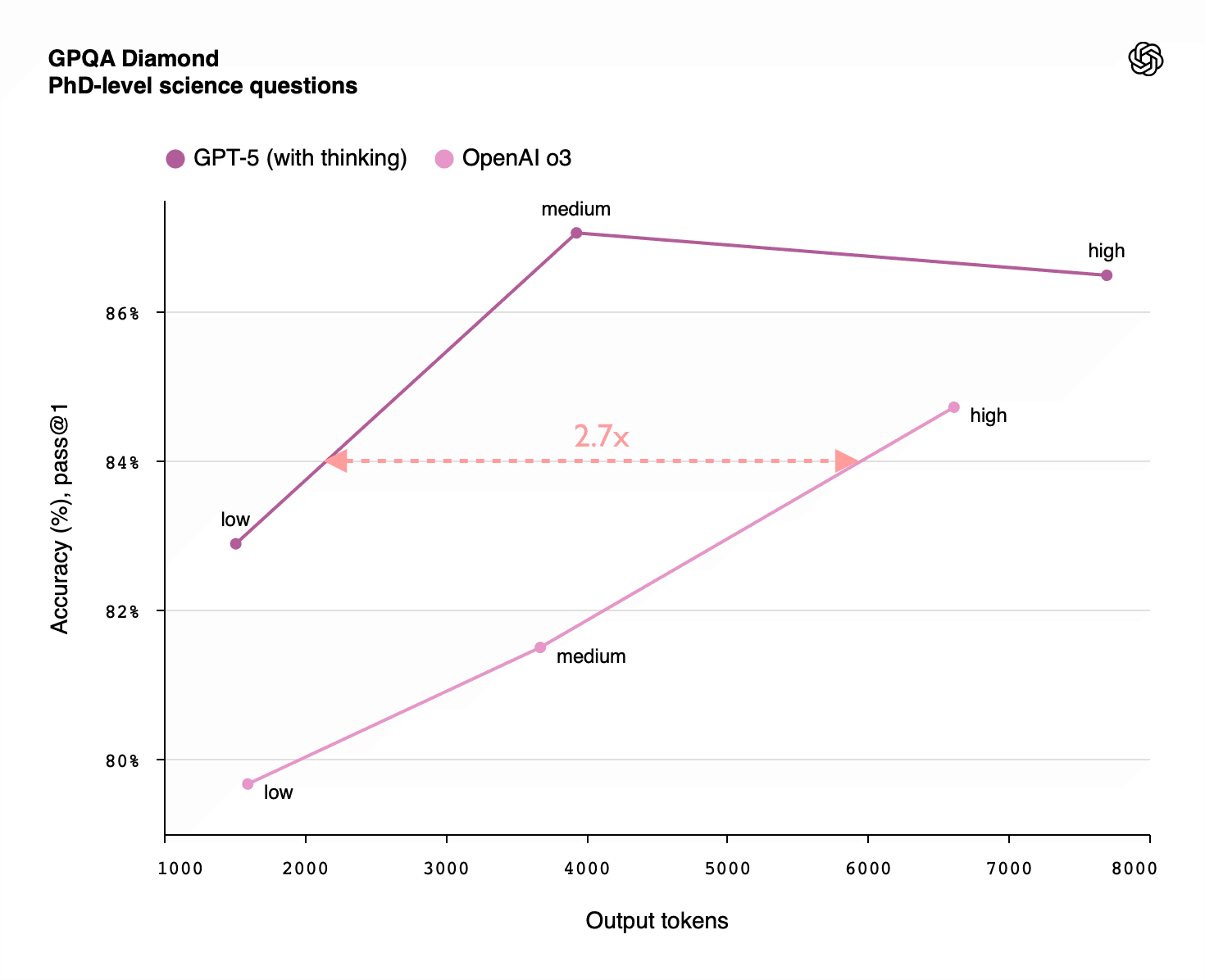
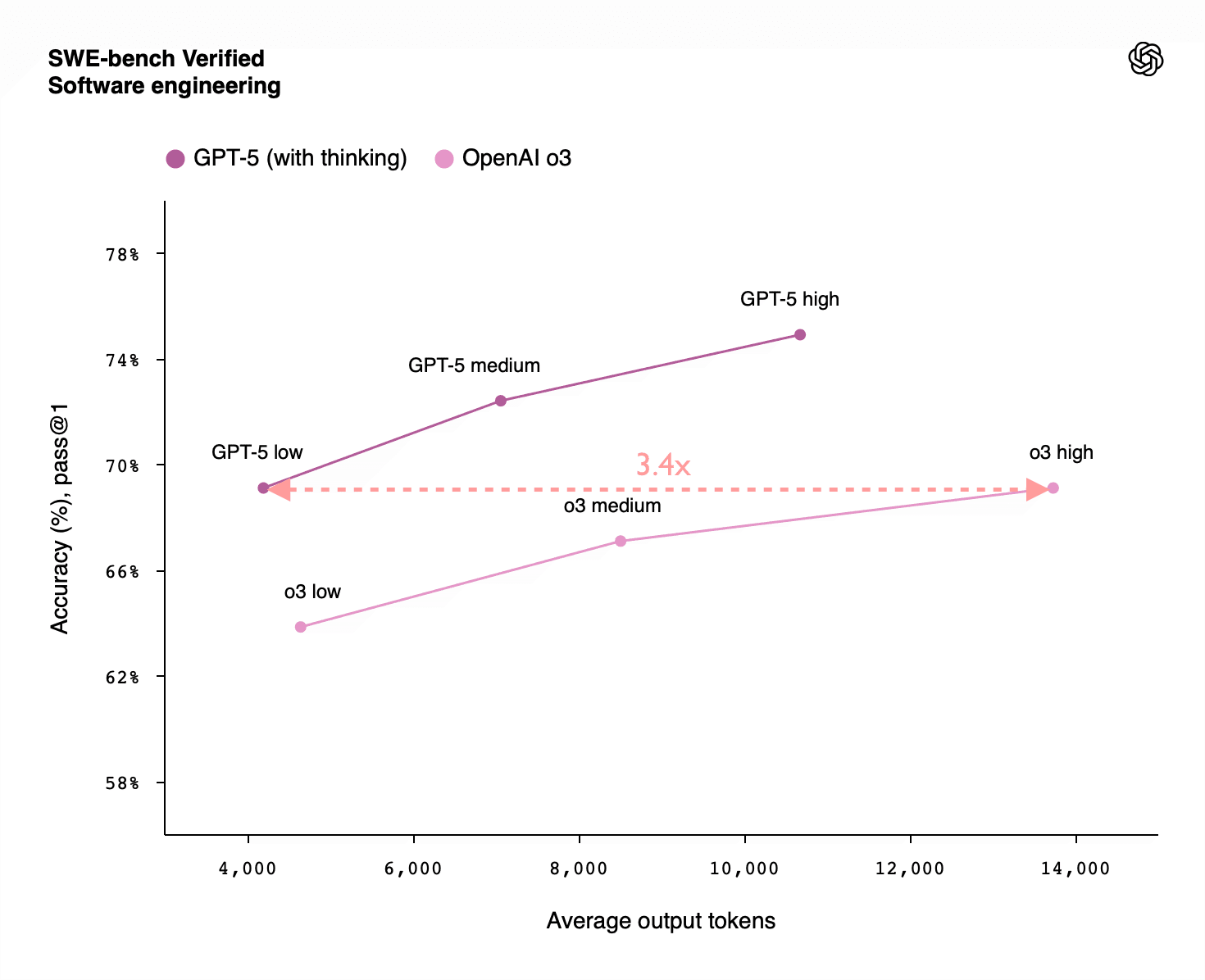
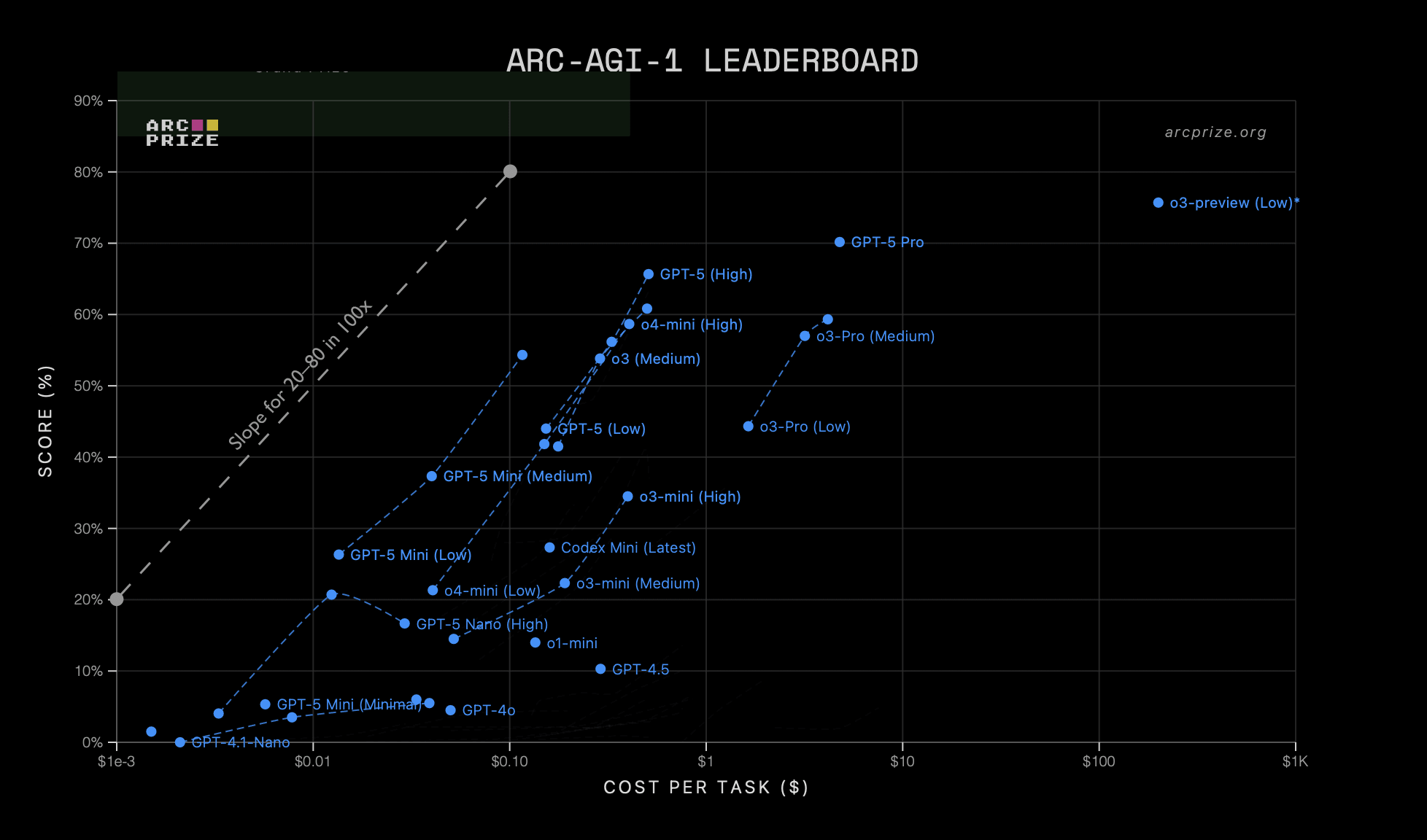
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
…
continue reading
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
- Scaling the amount of compute used for RL during training
- Scaling [...]
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
664 епізодів
Manage episode 516788581 series 3364760
Вміст надано LessWrong. Весь вміст подкастів, включаючи епізоди, графіку та описи подкастів, завантажується та надається безпосередньо компанією LessWrong або його партнером по платформі подкастів. Якщо ви вважаєте, що хтось використовує ваш захищений авторським правом твір без вашого дозволу, ви можете виконати процедуру, описану тут https://uk.player.fm/legal.
This is the latest in a series of essays on AI Scaling.
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
…
continue reading
You can find the others on my site.
Summary: RL-training for LLMs scales surprisingly poorly. Most of its gains are from allowing LLMs to productively use longer chains of thought, allowing them to think longer about a problem. There is some improvement for a fixed length of answer, but not enough to drive AI progress. Given the scaling up of pre-training compute also stalled, we'll see less AI progress via compute scaling than you might have thought, and more of it will come from inference scaling (which has different effects on the world). That lengthens timelines and affects strategies for AI governance and safety.
The current era of improving AI capabilities using reinforcement learning (from verifiable rewards) involves two key types of scaling:
- Scaling the amount of compute used for RL during training
- Scaling [...]
---
Outline:
(09:46) How do these compare to pre-training scaling?
(14:16) Conclusion
---
First published:
October 22nd, 2025
Source:
https://www.lesswrong.com/posts/xpj6KhDM9bJybdnEe/how-well-does-rl-scale
---
Narrated by TYPE III AUDIO.
---
664 епізодів
All episodes
×Ласкаво просимо до Player FM!
Player FM сканує Інтернет для отримання високоякісних подкастів, щоб ви могли насолоджуватися ними зараз. Це найкращий додаток для подкастів, який працює на Android, iPhone і веб-сторінці. Реєстрація для синхронізації підписок між пристроями.
Схожі до LessWrong (Curated & Popular)
The award-winning WIRED UK Podcast with James Temperton and the rest of the team. Listen every week for the an informed and entertaining rundown of latest technology, science, business and culture news. New episodes every Friday.
…
continue reading
BBC Radio 5 live’s award winning gaming podcast, discussing the world of video games and games culture.
…
continue reading
The director’s commentary track for Daring Fireball. Long digressions on Apple, technology, design, movies, and more.
…
continue reading
The power of Data is undeniable. And unharnessed - it's nothing but chaos. Making data your ally. Using it to lead with confidence and clarity. Host Jess Carter is solving problems in real-time to reveal what's possible. Helping communities and people thrive. This is Data Driven Leadership, a show brought to you by Resultant.
…
continue reading
Hanselminutes is Fresh Air for Developers. A weekly commute-time podcast that promotes fresh technology and fresh voices. Talk and Tech for Developers, Life-long Learners, and Technologists.
…
continue reading
WSJ’s Bold Names brings you conversations with the leaders of the bold-named companies featured in the pages of The Wall Street Journal. Hosts Tim Higgins and Christopher Mims speak to CEOs and business leaders in interviews that challenge conventional wisdom and take you inside the decisions being made in the C-suite and beyond.
…
continue reading
We help founders make something people want. The Y Combinator Podcast is where builders talk about building. From the earliest days of an idea to scaling a company that changes the world, YC partners and founders share real stories, lessons, and tactics from the frontlines.
…
continue reading
Android Backstage, a podcast by and for Android developers. Hosted by developers from the Android engineering team, this show covers topics of interest to Android programmers, with in-depth discussions and interviews with engineers on the Android team at Google. Subscribe to Android Developers YouTube → https://goo.gle/AndroidDevs
…
continue reading
Redefining AI is the 2024 New York Digital Award winning tech podcast! Discover a whole new take on Artificial Intelligence in joining host Lauren Hawker Zafer, a top voice in Artificial Intelligence on LinkedIn, for insightful chats that unravel the fascinating world of tech innovation, use case exploration and AI knowledge. Dive into candid discussions with accomplished industry experts and established academics. With each episode, you'll expand your grasp of cutting-edge technologies and ...
…
continue reading
Big tech is transforming every aspect of our world. But how, and at what cost? This season of Land of the Giants – The Disney Dilemma – focuses on Disney’s ability to weather the ups and downs of the business cycle and changing tastes and explores what has kept it successful for over 100 years. The entertainment giant has leveraged nostalgia and its intellectual property to build a beloved brand, but after an acquisition spree that included Marvel, Lucasfilm, and 20th Century Fox, can it sus ...
…
continue reading
Player FM - додаток Podcast
Переходьте в офлайн за допомогою програми Player FM !
Переходьте в офлайн за допомогою програми Player FM !



